






Наконец улеглись эмоции вокруг крупной утечки исходного кода «Яндекса», часть которого была выложена в публичный доступ 25 января. Настало время отделить хайп и подвести итоги, сделать полезные выводы из анализа кода.
- Введение
- Актуальность «слитых» данных
- Содержимое утечки
- «Яндекс» или Google: что выбрать?
- Поисковый механизм «Яндекса» изнутри
- Факторы ранжирования
- Применяет ли «Яндекс» прослушивание?
- Анализ содержимого утечки
- Необычные признаки ранжирования в «Яндексе»
- Выводы
Введение
Самой громкой новостью последних недель стала утечка из репозитория исходного кода «Яндекса». Сегодня называют несколько разных причин появления этих данных в публичном доступе. Официально «Яндекс» объявил, что утечка произошла в результате кражи данных бывшим сотрудником компании. Это не противоречит фактам: неизвестный создал для этого новый аккаунт и выложил данные анонимно в свободный доступ в виде торрента на одном из онлайн-форумов. В то же время многое указывает, что выкладка была сделана не ради мести или корысти, а по политическим мотивам. Это — ещё один знак для служб ИБ, что данный мотив является сегодня одним из главных для мониторинга.
Как уже сообщалось, объём обнародованного кода составил примерно 45 ГБ. Данные быстро «расползлись» по сети, поэтому фрагменты теперь доступны экспертам и в обычном, не теневом вебе.
В открытый доступ попали только данные относящиеся к алгоритмической части программных механизмов «Яндекса», в том числе его поисковой системы. Они позволяют лучше понять особенности работы поисковой системы, но не дают возможности сделать клон. Нет там также и персональных данных, стоп-слов, обученных языковых моделей, словарных фраз для анализа контента.
«Слив» такого масштаба можно считать исключительным. Подобный инцидент встречался ранее только в 2006 году, когда в публичный доступ попал исходный код веб-сервиса AOL. Тогда его изучение позволило многим воспользоваться техническими инновациями AOL. В определённой мере это способствовало продвижению инноваций на рынке.
Нынешняя утечка не раскрывает «патентованных» секретов. Несмотря на обилие кода, контент подобран грамотно. Это может косвенно свидетельствовать в пользу политической версии инцидента.
«Яндекс» подтвердил факт кражи и достоверность данных. Компания извинилась перед своими клиентами и всеми, кто мог пострадать из-за этой утечки. «Яндекс» также опубликовал результаты внутреннего расследования, официально заявив, что обнародованные фрагменты кода не несут угрозы для безопасности и работоспособности сервисов. Кроме того, «Яндекс» признал, что были серьёзно нарушены политики ИБ и этические принципы.
Актуальность «слитых» данных
Главный вопрос в отношении любой утечки — это степень актуальности данных. «Неизвестный» заявил, что они датированы июлем 2022 года. Это видно по скриншоту поста, который опубликовало издание BleepingComputer.
Независимая проверка подтверждает эти данные. Например, дата последней регистрации изменений в списке факторов ранжирования — 24.03.2022. В этом же списке имеются ссылки на ответственных работников, которые совпадают с именами реальных сотрудников «Яндекса».
По словам экспертов, попыток продажи этих данных ранее не было. В то же время все файлы датированы 24 февраля 2022 г., что служит намёком на политический мотив «слива».
Рисунок 1. Публикация утечки (BleepingComputer)
")
Содержимое утечки
Среди важных деталей утечки можно отметить следующее:
- Архив содержит файлы исходного кода (Python, структуры данных и пр.). Файлы настройки поискового механизма (стоп-слова, регулярные фразы и пр.) отсутствуют.
- Нет файла с описанием истории изменений Git-репозитория.
- Отсутствуют скомпилированные двоичные файлы для большей части выложенного ПО (за некоторыми исключениями).
- Нет файлов предварительно обученных моделей машинного обучения (за некоторыми исключениями).
В выкладке есть список факторов ранжирования, используемых для формирования поисковых выдач и взвешивания ссылок. Каждый фактор имеет описание и ссылку на служебный вики-ресурс «Яндекса». Там, похоже, хранятся фактические данные для настройки, но доступ к ним требует авторизации. Персональные данные в выкладке отсутствуют.
Рисунок 2. Содержимое файла с описанием факторов ранжирования
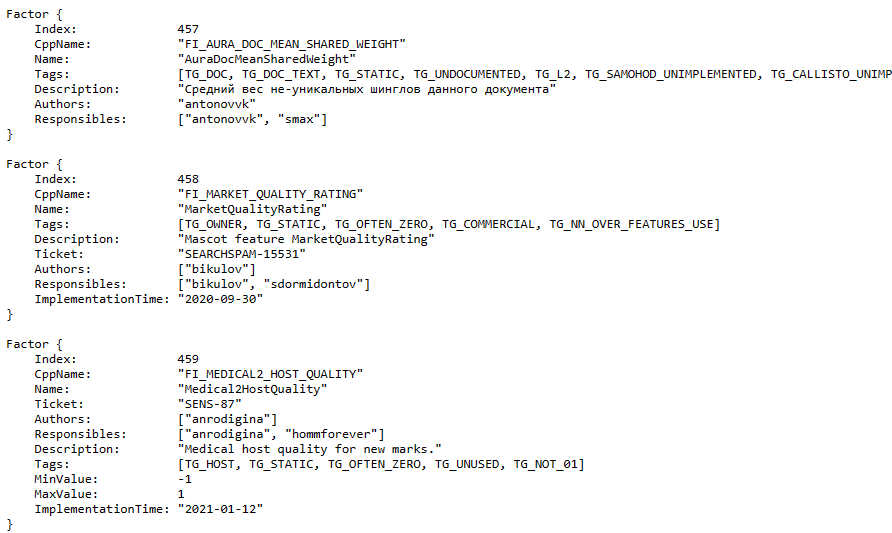
Анализ содержимого, проведённый А. Шестаковым (первым опубликовал общий разбор утечки данных), позволяет определить принадлежность контента различным продуктам «Яндекса» (по именам директорий):
- Поисковый механизм и сервис индексации.
- «Карты».
- «Алиса».
- «Такси».
- «Директ» (рекламная служба).
- «Почта».
- «Диск» (облачный файловый хостинг).
- «Маркет».
- «Путешествия» (букинг-платформа).
- «360» (управление рабочим пространством).
- Yandex Cloud.
- Yandex Pay (служба процессинга платежей).
- «Метрика» (интернет-аналитика).
Достоверность утечки подтвердил бывший топ-менеджер «Яндекса» Григорий Бакунов, который до 2019 года работал в киевском офисе компании. Он подтвердил также, что попытки продажи данных не было, и отметил, что прямой угрозы распространения проприетарных, защищённых технологий «Яндекса» нет.
Защищённость «чувствительных» данных была обеспечена за счёт их размещения в монорепозитории Arcadia. Применённый способ хранения (создан в 2013 году) заставляет даже для простой сборки сервиса подключать ряд внутренних инструментов и специальных баз знаний (вики), которые отсутствуют в архиве. Благодаря этому среди утёкших данных не оказалось ключевых компонентов механизмов «Яндекса»: конкретных данных для их настройки, весов для нейронных сетей и т. д. Выложенные данные пригодны только для образовательных и ознакомительных целей.
«Яндекс» или Google: что выбрать?
Произошедшая утечка позволяет более аргументированно ответить на вопрос, который до сих пор нередко встречается в обсуждениях: какую поисковую систему лучше использовать — «Яндекс» или Google?
Они различаются в деталях. Например, можно сравнить разное отношение к метрике CTR («коэффициент кликабельности», Click-Through Rate). Это — популярный признак, который позволяет проводить сравнение разных ссылок с опорой на отношение числа переходов по ссылке к числу её отображений в поисковой выдаче. Эту метрику активно используют SEO-специалисты, решающие задачу поднять ссылки вверх в поисковой выдаче. Метрика CTR служит объективным подтверждением эффективности их работы.
О широком применении метрики CTR заговорили после 2006 года после утечки кода из AOL, где её, похоже, первыми и придумали. По новому сливу видно, что «Яндекс» активно применяет CTR (производные на его базе) до сих пор.
Google (со слов её руководителей) не стала применять CTR напрямую как сигнал к повышению уровня ссылки. Google рассматривает эту метрику как «описательный» признак и нашла для неё применение в своих онлайн-инструментах для SEO. По оценкам Google, она помогает «информировать владельцев веб-сайтов, насколько эффективно их страницы работают в поиске Google». Эта информация стимулирует доработку веб-страниц для повышения их рейтинга в поисковой выдаче Google, но напрямую Google не использует CTR.
В целом ясно, что две компании применяют схожие поисковые алгоритмы. По утёкшим данным также видно, что в «Яндексе» активно используют ряд открытых технологий Google: библиотеку TensorFlow для построения и обучения нейронных сетей, модель обучения BERT для обработки текстов на естественном языке, модель распределённых вычислений MapReduce для параллельной обработки массивных наборов данных и др. По словам экспертов, в «Яндексе» частично используются также и элементы протокола сериализации Protocol Buffers для структурированных данных, которые помогают переводить данные в бинарный вид.
Поисковый механизм «Яндекса» изнутри
«Яндекс» называет свой поисковый механизм двухуровневым, опираясь на выбранную им технологию обновления ссылок. Он использует роботы двух типов: «Main Crawler» и «Orange Crawler». Первые выполняют общий плановый обход интернета, вторые служат для выполнения срочных задач в настоящем времени.
Рисунок 3. Двухуровневая модель «Яндекса» для сбора данных в интернете

Google использует более сложный, трёхуровневый алгоритм для обхода сети. Её роботы первого типа обеспечивают экстренное сканирование в настоящем времени, второго типа — регулярный обход интернета, третьего типа — проверочное сканирование.
Google не даёт явных объяснений, какие причины заставляют выполнять проверочное сканирование. Видимо, это связано с обнаружением расхождений между ранжированием ссылки и регистрируемой реакцией пользователей. Возможен также вариант, что Google использует какой-то механизм перепроверки параметров ссылок и в случае резких изменений запускает повторный поиск. Этот дополнительный, обучаемый ИИ-инструмент может играть роль средства обратной связи.
Как бы то ни было, эксперты считают трёхуровневый подход Google более надёжным. В то же время для его реализации требуется больше ресурсов.
Главное различие между «Яндексом» и Google касается механизма рендеринга сайтов. «Яндекс» не выполняет прямого рендеринга JavaScript-кода, как это делает Google. Для этих целей «Яндекс» применяет программный механизм Gemini, обеспечивающий регрессионный анализ результатов работы JS-элементов. Используется также опенсорсный механизм Selenium WebDriver.
В остальном, по мнению экспертов, «Яндекс» и Google применяют схожие алгоритмы обработки данных. В ходе рендеринга ссылок выполняется индексация данных, создаются кеш-копии страниц, заполняется словарь буквенных конструкций. Яндекс применяет двух- и трёхсимвольные сочетания (биграммы и триграммы), Google — более сложные фразовые конструкции (n-граммы).
Факторы ранжирования
По файлам утечки видно, что с 2018 года «Яндекс» начал отслеживать даты внесения изменений в список факторов ранжирования. Это позволяет оценить интенсивность обновлений. Если в 2018 году в базе появилось 206 новых записей, то далее динамика резко пошла на убыль: 2019 — 62 обновления, 2020 — 80, 2021 — 16, 2022 — 18. Можно предположить, что «Яндекс» считает свой алгоритм полностью выстроенным.
Проведённый анализ позволил исследователям дать несколько оценок:
- Значительная часть факторов ранжирования в «Яндексе» совпадает с теми, что использует Google.
- Большинство уникальных факторов внесены для отражения специфики российского интернета.
- Фаза активного учёта ссылки в поисковой выдаче «Яндекса» ограничена 1600 днями (примерно 4,4 года).
- «Яндекс» делит ссылки на группы: «торговля», «путешествия», «еда», «реклама», «здоровье», «для взрослых» и т. д.
Применяет ли «Яндекс» прослушивание?
Тема «прослушки» всегда вызывает повышенный интерес на рынке. Она отражает страхи, бытующие среди пользователей. Потому нет ничего удивительного в том, что эта тема сразу всплыла после «слива». В СМИ заговорили о якобы найденном коде для слежки через голосовой помощник «Алиса».
Яндекс быстро опроверг подозрения, заявив, что не занимается прослушкой через «умные» устройства. Было заявлено, что алгоритм включения микрофона работает только для целей бета-тестирования.
Как показывает практика, часто метрики, которые принимаются за признаки «прослушки», на самом деле предназначены для работы ИИ-систем. Например, среди метрик «Яндекса» встречаются такие индикаторы, как отказ от посещения страницы, одновременное посещение страницы в группе ссылок по одному запросу, время пребывания на сайте и т. д. Аналогичные метрики исследовали и в Google, хотя в американской компании пришли к выводу, что они не обладают достаточной релевантностью для практического использования. Тем не менее Google «засвечивает» применение различных поведенческих характеристик в таких инструментах, как Google Analytics и Google Chrome.
Сравнивая подходы «Яндекса» и Google к регистрации поведенческих характеристик, эксперты склоняются ко мнению, что Google придерживается более строгой оценки пользователей, тогда как «Яндекс» старается сделать её более индивидуальной.
Например, «Яндекс» уделяет больше внимания тому, чтобы его поисковая выдача лучше соответствовала местонахождению пользователя. Google больше ориентируется на контентное содержание и старается не злоупотреблять данными о местоположении. По словам представителей Google, это делается прежде всего потому, что подобные параметры активно используют спамеры, которые могут легко манипулировать ими.
Эксперты также отмечают, что алгоритм ранжирования текстов, применяемый «Яндексом», более склонен к «обесцениванию» больших по объёму текстов. «Яндекс» отдаёт предпочтение более компактным текстам, тогда как Google старается не обращать большого внимания на объём текста, а оценивает в первую очередь степень полезности контента и степень его соответствия запросу.
В то же время исследователи обнаружили в коде «Яндекса» фрагменты предназначенные для отправки явно вспомогательной информации на служебные серверы. К таким данным относились закодированные по стандарту Base64 имя хоста, имя текущего рабочего каталога и некоторые другие параметры. В описании вкраплений кода указывалось, что они предназначены для тестирования функций защиты («meow! security test»).
Рисунок 4. «Сомнительный» отладочный фрагмент в коде «Яндекса»

Анализ содержимого утечки
Среди пользователей до сих пор сохраняется убеждение, что фундаментальным методом реализации поиска всё ещё остаётся алгоритм PageRank. Он применяется для ранжирования страниц, измеряя «важность» (или «авторитетность») через подсчёт количества имеющихся ссылок на документ и их собственных рейтингов. Патент PageRank лёг в основу создания поисковика Google.
Как показал слив кода «Яндекса», поддержка алгоритма PageRank в российской системе сохраняется до сих пор, но в адаптированном варианте. Ранее Google также подтвердила, что поддержка PageRank всё ещё присутствует в её алгоритмах ранжирования, отметив при этом, что его влияние на поисковую выдачу сегодня гораздо ниже.
В целом оба ядра («Яндекс» и Google) обрабатывают запросы схожим образом. Первым делом они проверяют попадание текущего поискового запроса в индекс популярных результатов. Если этого не наблюдается, то запрос отправляют одновременно в адрес тысяч виртуальных машин, каждая из которых выполняет собственный поиск для частного набора приоритетов. Поисковая машина собирает полученные от ВМ рекомендации, отбрасывает «опоздавших» и суммирует их в итоговую выдачу.
Анализ кода «Яндекса» позволил исследователям выделить пять наиболее важных признаков, по которым создаётся итоговый ответ для «Яндекса». Они также назвали топ-5 признаков, которые служат для отбраковки рекомендаций.
Топ-5 «премиальных» признаков для попадания в список ранжирования:
- «Маскирующим» поднятием веса является применение в URL-адресе триграмм, которые встречаются в поисковом запросе пользователя. Например, из запроса «Челябинская лотерея» можно получить набор триграмм «che, hel, lot, olo»; они сразу указывают на приоритетность URL-адресов, в которых есть слово «chelloto».
- Неизвестный признак, который «умело сочетает FRC и псевдо-CTR». Похоже, он выполняет псевдоучёт коэффициента кликабельности.
- Частота выбора пользователями определённой ссылки в поисковой выдаче.
- Соответствие контента тем словам, которые пользователи задают для поиска (т. е. «Яндекс» активно применяет обратную связь).
- Принадлежность к доменной зоне «.com»: при прочих равных условиях приоритет отдаётся документу из неё.
Топ-5 «штрафных» признаков:
- Присутствие на странице рекламы любого рода.
- Вторичность по дате. При одинаковых условиях предпочтение отдаётся более раннему документу.
- Частота показов. «Яндекс» старается разнообразить выдаваемые результаты, поэтому на одинаковые запросы пользователи будут получать разные поисковые выдачи.
- Слишком частое использование «броских» фраз: «Яндекс» играет по правилам «Антиплагиата».
- Географическая близость источника документа и страны, из которой пользователь выполняет поиск. «Яндекс» неохотно выдаёт документы из других географических локаций.
Полученные «правила» помогают сформулировать ряд рекомендаций, которые могут быть полезны для подъёма ссылки в поисковой выдаче «Яндекса»:
- избегать рекламных фраз и текстовых «штампов»;
- обновлять контент страницы, а не публиковать новый материал взамен устаревшего;
- стремиться к уникальности текста.
Для медийных источников «Яндекс», похоже, использует привилегированный список. Попадание в него резко повышает цитируемость в поисковой выдаче вне зависимости от того, насколько активно пользователи реагируют на этот контент.
Для поднятия цитируемости в поисковых выдачах также полезно:
- Использовать «значимые» названия файлов или каталогов.
- Публиковаться в домене из зоны «.com».
- Повышать кликабельность текстов (возможно, даже искусственно).
- Публиковать тексты на ресурсах, которые более близки к целевой аудитории географически.
Необычные признаки ранжирования в «Яндексе»
Эксперты отмечают присутствие в файлах утечки «Яндекса» ряда необычных факторов ранжирования. Отдельные из них приведём далее.
- Учитывается время отправки поискового запроса (искать деловые материалы лучше в рабочее время).
- PageRank занимает 17-е место по значимости в списке факторов ранжирования «Яндекса», но этот параметр оказался более значимым, чем, например, признак соответствия темы контента запросу (19 место).
- Если зафиксирован взлом сайта, то значимость его контента для поисковой выдачи резко падает.
- «Яндекс» использует списки из 200 и 500 наиболее часто употребляемых слов (по другой версии — классов слов). Рассчитывая их долю на странице, он определяет уровень оригинальности текста.
- «Яндекс» оценивает Whois-данные сайта и рассчитывает по ним степень его похожести на спам. Размещение страниц со спамом понижает ранг веб-сайта в целом, делая менее значимыми другие страницы.
- Статьи из «Википедии» попадают в верхнюю часть поисковой выдачи.
- «Яндекс» специально выделяет короткие видеоролики (TikTok, Instagram Reels, YouTube Shorts).
- «Яндекс» повышает значимость постов в телеграм-каналах и TikTok, но игнорирует публикации в Twitter.
- Значимость страницы резко растёт, если пользователи остаются на ней более 90 секунд.
- «Яндекс» сравнивает количество просмотров ссылки с настольных и мобильных устройств, поэтому поисковые выдачи для мобильных и стационарных устройств будут разными.
- «Яндекс» блокирует выдачу контента защищённого антипиратским меморандумом.
Выводы
Утечка из «Яндекса» получила большой общественный резонанс. Это лишний раз показывает, насколько важно заблаговременно побеспокоиться о безопасности не только веб-сайтов, но и средств веб-разработки.
Несмотря на это, данная утечка не имела для «Яндекса» катастрофических последствий, прежде всего репутационных. В то же время разумно проводить ревизию внутреннего контента, чтобы минимизировать подобные риски даже в случае форс-мажора.




