













Пользователи Android всё чаще отказываются от приложений и VPN для блокировки рекламы, выбирая Private DNS как самый простой и эффективный способ защиты. Опрос показал, что DNS-сервисы вроде AdGuard и Cloudflare позволяют убрать рекламу, снизить риск мошенничества и не замедлять работу смартфона.
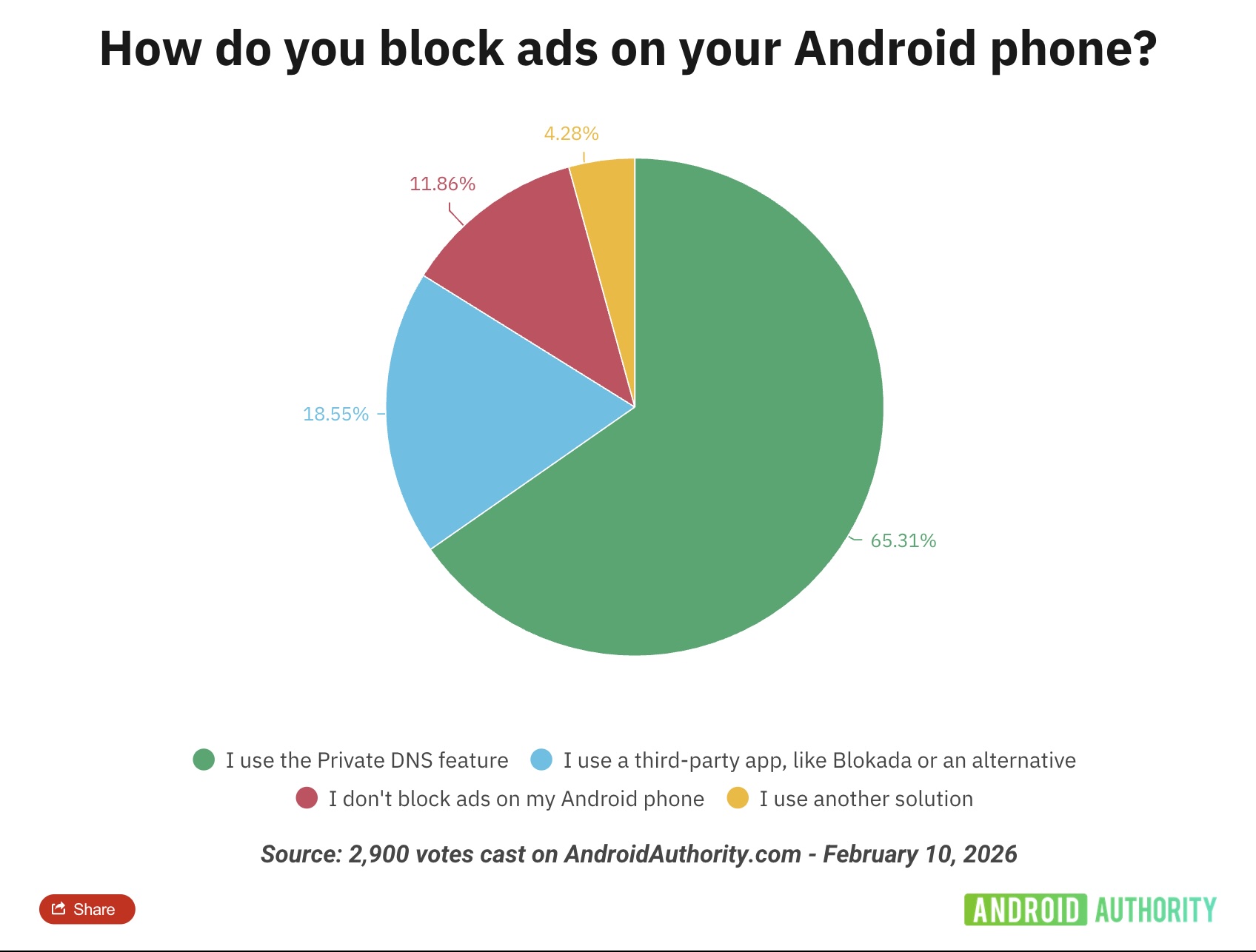
Как выяснили исследователи, самым популярным способом блокировки рекламы стал Private DNS. Этот вариант заметно опередил все остальные.
Около 65% респондентов сообщили, что используют Private DNS, например Cloudflare 1.1.1.1 или специализированные решения вроде AdGuard DNS. Такие сервисы легко настраиваются, не требуют установки сторонних приложений и позволяют отсеивать рекламные и потенциально опасные домены на уровне запросов.
Для сравнения: менее 19% пользователей предпочитают сторонние приложения для блокировки рекламы, такие как Blokada. Совсем небольшая доля респондентов призналась, что вообще не использует никакие инструменты для защиты от рекламы.
Пользователи отмечают сразу несколько преимуществ DNS-подхода:
- он не нагружает систему и не замедляет интернет, как это иногда бывает с VPN;
- не конфликтует с сервисами вроде Android Auto;
- помогает фильтровать не только рекламу, но и фишинговые или сомнительные сайты;
- настраивается за пару минут прямо в системных параметрах Android.
При этом Private DNS не ограничивает доступ к сервисам и не ломает работу приложений, что для многих оказалось решающим фактором.
Помимо DNS-сервисов, пользователи активно рекомендуют браузеры с встроенной блокировкой рекламы. Среди популярных вариантов — Firefox с расширением uBlock Origin и фирменный браузер Samsung, который поддерживает контент-блокеры из коробки.
Некоторые, наоборот, выбирают отдельные приложения для блокировки рекламы. Такой подход может быть удобнее, например, в корпоративной среде, где важно, чтобы инструменты защиты корректно работали с бизнес-приложениями.



