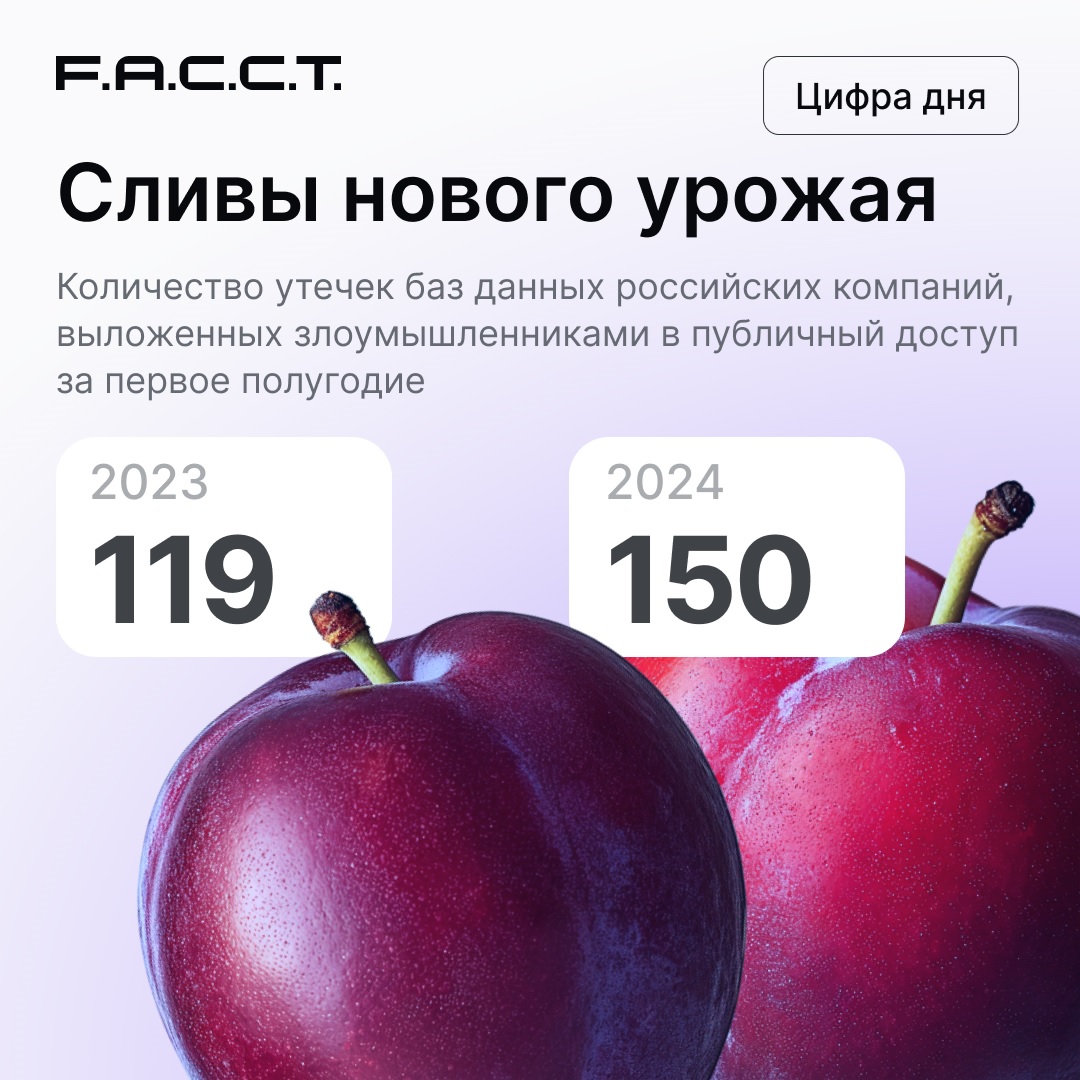
Специалисты компании F.A.C.C.T. привели интересную статистику: за первые шесть месяцев 2024 года в открытый доступ выложили 150 баз данных российских компаний. Каждая из этих БД впервые просочилась в Сеть.
Аналогичный период прошлого года показал лишь 119 скомпрометированных баз, а за весь 2023-й в общем доступе оказались 246 БД.
Организации сферы ретейла составили 30% от общего числа утечек за первое полугодие 2024-го. Чаще всего в слитых базах можно найти ФИО, адреса проживания, пароли, даты рождения, паспортные данные и телефонные номера.
Большинство БД датируются 2024 годом, а общее число строк составило 200,5 млн. Для сравнения: в прошлом году было 397 млн строк, в 2022-м — 1,4 млрд, а в 2021-м — 33 млн.
Помимо сферы розничной торговли, от утечек пострадали российские ИТ-компании, страховые, энергетические, туристические и транспортные организации, а также образовательные порталы, сервисы доставки, промышленные предприятия и медицинский сектор.