












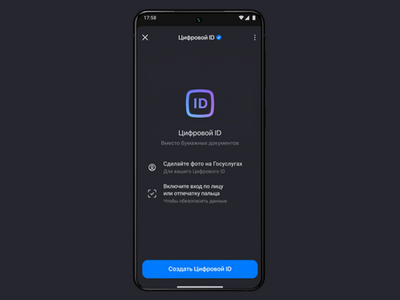
Процедура получения льгот, вводимых российским ретейлом для людей преклонного возраста, скоро упростится. Таким покупателям достаточно будет зайти в MAX и предъявить на кассе QR-код, сгенерированный на основе цифрового ID.
Сервис подтверждения статуса пенсионера через MAX уже запущен в пилотном режиме компанией X5.
В настоящее время нововведение доступно лишь москвичам — посетителям ряда «Перекрестков» и «Пятерочек», освоившим самообслуживание. В следующем месяце планируется распространить его на все торговые точки этих сетей.
«Каждый месяц в наши магазины приходят около 20 млн покупателей пенсионного возраста, — отметил Александр Костин, управляющий директор Х5 Tech. — Мы последовательно развиваем цифровые сервисы, которые делают покупки для клиентов любого возраста быстрее и удобнее, а процессы в магазинах — более эффективными».
Воспользоваться новой функцией несложно. На кассе самообслуживания нужно отсканировать товар, открыть раздел «Скидки пенсионерам и другие», выбрать из списка «Скидка пенсионерам» и поднести к считывателю смартфон с QR-кодом в профиле MAX (в мессенджере на такие случаи предусмотрена опция «Показать ID»).
Возможность использования MAX для подтверждения возраста в России закреплена законом. Создаваемый в мессенджере цифровой ID разрешено применять с этой целью наравне с бумажными документами, и ретейлеры уже начали осваивать это новшество при продаже товаров 18+.



