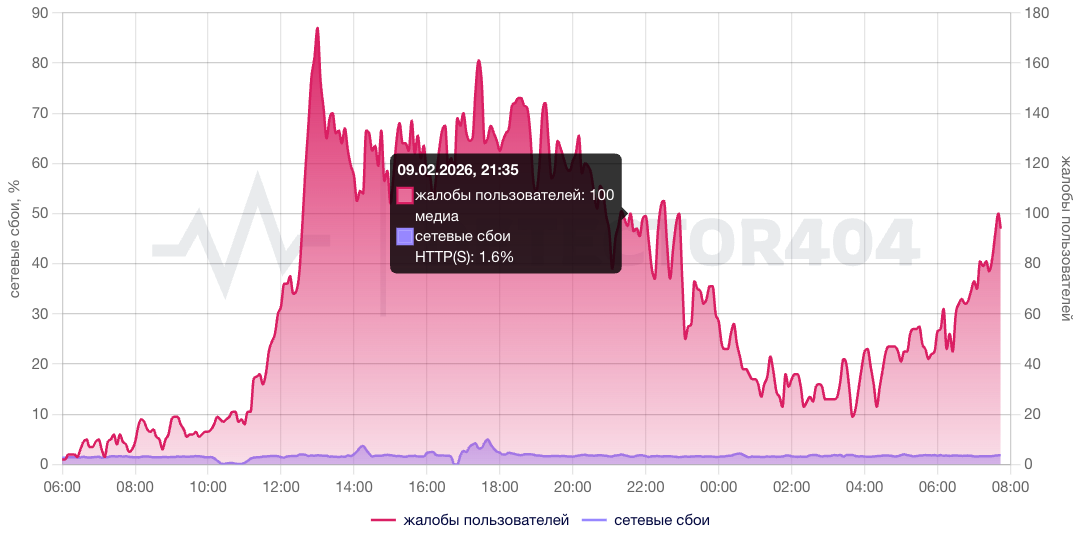
В России Telegram работает с заметными перебоями, особенно при загрузке «тяжёлого» контента. При этом глобально проблем в работе мессенджера не зафиксировано. Пользователи жалуются на сложности с загрузкой видео и фотографий, прежде всего в высоком разрешении.
Судя по данным сервиса Detector404, проблемы начались ещё вечером 9 февраля. Наибольшее количество жалоб связано с работой веб-версии Telegram.
Аналогичная картина наблюдается и на сервисе Сбой.РФ. «Telegram замедлился до скорости 3G», — отметил один из пользователей в комментариях. В основном речь идёт о трудностях с загрузкой видео и голосовых сообщений.
При этом, по словам пользователей, использование «дополнительных сетевых средств» полностью нормализует работу сервиса. Одновременно с этим, согласно данным глобального сервиса Downdetector, серьёзных сбоев в работе Telegram не зафиксировано.
Сообщения о точечных вмешательствах в работу мессенджера начали появляться в середине января 2026 года. Спустя несколько дней сенатор Артём Шейкин заявил, что Роскомнадзор «применяет меры» в отношении Telegram в ответ на нарушения законодательства.